
ডাটা সাইন্স দিয়ে একটা রোডম্যাপ - একদম শুরু থেকে। ফর অ্যাবসলিউট বিগিনার্স! পিএইচডি দরকার নেই এই ডাটা সাইন্স করতে!
Recipes tell you nothing. Learning techniques is the key.
— Tom Colicchio
ডাটা সাইন্স/অ্যানালিটিক্স নিয়ে অনেক ধরনের ‘আলাপ’ চালু আছে ইন্ডাস্ট্রিতে, বিশেষ করে কিভাবে এবং কতো সময়ের মধ্যে একজন ভাল ডাটা সাইন্টিস্ট/অ্যানালিটিক্স হওয়া যায়। এটার উত্তর অনেকটাই আপেক্ষিক কারণ ডাটার ব্যাপারে কে কিভাবে ভাবছে, তার উপর নির্ভর করছে কে ডাটা নিয়ে কোন লেভেল পর্যন্ত কাজ করতে চাইবেন। ডাটা নিয়ে কাজ করতে হলে শুরুতে ডাটা অ্যানালিটিক্স (ডাটা থেকে জ্ঞান) দিয়ে শুরু করা যেতে পারে। তবে, ডাটা অ্যানালিটিক্স (ক্ষেত্র বিশেষে ৫-৬ মাস) দিয়ে শুরু করে ডাটা সাইন্স (১২-১৬ মাস) এর মধ্যে করা সম্ভব।
ডাটা সাইন্স একটা মহীরুহ জিনিস (বটগাছ), - তবে, আমার মতে ডাটা সাইন্স এর মত গভীর বিষয়ে যাবার আগে ডাটা থেকে কিভাবে “ইনসাইট” নিতে হয় (ডাটা অ্যানালিটিক্স) সেটা বুঝতে পারলে আস্তে আস্তে “ডাটা সায়েন্স” নিয়ে কাজ করা সুবিধাজনক হবে। ডাটাকে কিভাবে ‘হ্যান্ডেল’ করা হচ্ছে, এর পাশাপাশি সেই ডাটা কি ধরনের আউটকাম দিতে পারে - সেগুলো বোঝা গেলে ডাটা সম্পর্কিত এই সাইন্স বোঝা অনেকটাই সোজা হয়ে যায়। যারা হাজারো ডাটা সায়েন্স নিয়ে বিভিন্ন টিউটোরিয়াল দেখছেন, তাদের বেসিক ধারনা ঠিক না থাকার ফলে মাঝ পথ থেকেই আগ্রহ হারিয়ে ফেলছেন। সে কারণেই আমার এই গাইডলাইন।
আবারও বলছি,
এখানে সোজা এবং সিলেক্টিভ হচ্ছে, ডাটা অ্যানালিটিক্স রোড ম্যাপ, যার শুধুমাত্র * অংশগুলো নেয়া হয়েছে পুরো ডাটা সাইন্স রোড ম্যাপ থেকে। আবারও বলছি, ডাটা সাইন্স একটা মহীরুহ জিনিস (বটগাছ), শুরুতে ডাটা অ্যানালিটিক্স শেখা সহজ।
| সময়সীমা: | ডাটা সাইন্স/অ্যানালিটিক্স |
|---|---|
| ডাটা অ্যানালিটিক্স | ৫-৬ মাস |
| ডাটা সাইন্স | ১০-১৬ মাস |
যে কোনো জিনিস শেখার জন্য শুরুতে একটা লার্নিং ফ্রেমওয়ার্ক থাকা ভালো। এ ধরনের লার্নিং ফ্রেমওয়ার্কে কি কি জিনিস যোগ করতে হবে এবং তার জন্য কি ধরনের রিসোর্স এইমুহূর্তে পাওয়া যায় - প্লাস, তার সাথে কোন ধরনের টুল এই মুহূর্তে ব্যবহার হচ্ছে, সেগুলো নিয়ে ধারনা দেবার জন্যই এই রোডম্যাপ। লার্নিং ফ্রেমওয়ার্কটা একটা প্রসেস, প্রসেসগুলো ঠিকমতো বুঝে গেলে কোন ধরনের টুল সামনে ব্যবহার হবে সেটাও বোঝা যাবে - যেটা সময়ের সাথে পাল্টাবে।
এ কারণে আমি সাধারণত “টুল ডিপেন্ডেন্ট” হবার কথা বলি না। আমার কথা একটাই - প্রসেস ঠিকমত বুঝে গেলে যে কোন টুল শেখা সোজা। আমরা কি শিখবো, কেন শিখবো - কেন দরকার – সেটার সাথে ‘রেলেভেন্স’ আছে কিনা, সেটা জানাও দরকার ব্রডলাইনে।
লার্নিং রোডম্যাপ: ব্যাপারটা কি?
এটা অনেকটা মাইন্ড ম্যাপের মতো, যেখানে ‘মাল্টি-লেভেল’ স্কিল তৈরি করা খুব একটা কষ্টকর কিছু নয়। এখানে বলব, কি কি ধরনের স্কিল আমরা শিখতে চাইবো, এবং সেই প্রসেসগুলোর আউটকাম কিভাবে ‘মেজার’ করতে হবে, সেটা বুঝে গেলে আমাদের কাজ কমে আসবে। প্রতিটা লেভেলের প্রসেস এবং তার সম্পর্কিত টুলের ব্যবহার - সেগুলোও দেখব এখানে। এর পাশাপাশি, আমরা দেখবো, কি কি ধরনের টেকনিক কাজে দেবে প্রতিটা স্কিলকে মাস্টারিং করতে। সেখানে, কোথায় গেলে এই জিনিসগুলো সহজে শেখা যাবে, অথবা কোন কোন জায়গায় ‘কম্প্লেক্সিটি’ বাড়তে পারে, সেটা দেখা যাবে সামনের ধাপগুলোতে।
ডাটা সাইন্স সামারি, (*) মার্ক = অ্যানালিটিক্স
| ডাটা সাইন্স | অ্যানালিটিক্স |
|---|---|
| ‘এন্ড টু এন্ড’ পাইপলাইন | ঐচ্ছিক |
| ‘হায়ারার্কি অফ নিডস’ | * |
| ডাটা সাইন্স ওয়ার্কস্পেস | |
| বেসিক অংক, লিনিয়ার এলজেবরা | |
| পরিসংখ্যান, ডিস্ট্রিবিউশন | * |
| প্রোগ্রামিং স্কিল, পাইথন/‘আর’ | * |
| এক্সপ্লোরাটরি ডাটা এনালাইসিস | * |
| ডাটা ভিজুয়ালাইজেশন | * |
| প্রফেশনাল ভিজুয়ালাইজেশন টুল | * |
| বিজনেস অ্যানালিটিক্স/ইন্টেলিজেন্স টুল | * |
| মডেল তৈরি, মেশিন লার্নিং | |
| সিক্যুয়েল স্কিল, SQL | * |
| নো সিক্যুয়েল (ঐচ্ছিক) | |
| ডাটা অ্যানালিটিক্স ক্যাপস্টোন প্রজেক্ট | * |
| ডাটা সায়েন্স ক্যাপস্টোন প্রজেক্ট | |
| ডাটা ইঞ্জিনিয়ারিং, এপিআই |
আমরা জানতে চাইবো - কিভাবে একজন সফল ডাটা সাইন্টিস্ট/অ্যানালিস্ট হওয়া যায়? একদম শুরুতে, (কয়েক লাইন এর) ছোট্ট ডাটা সম্পর্কিত একটা ‘এন্ড টু এন্ড’ প্রজেক্ট নিয়ে একটা সাধারণ ধারণা পাওয়া গেলে বাকি কাজগুলো খুব সহজ হয়ে যায়। শুরুতে ডাটা সাইন্স/অ্যানালিস্ট পাইপলাইন বোঝা জরুরি। ডাটা কিভাবে পাইপ দিয়ে একেকটা অপারেশনের মধ্য দিয়ে ট্রান্সফর্ম হচ্ছে সেটা না জানলে এই জিনিস বোঝা কষ্টকর। এজন্য দরকার দুটো প্রজেক্ট।
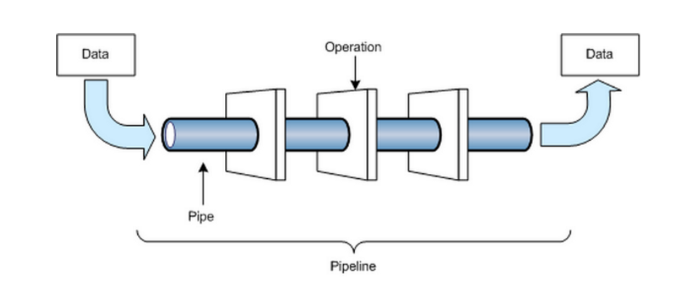
এরপরে থিউরি হিসেবে কিছু অংক এবং পরিসংখ্যানের ধারণা পেলে সামনে আগানো অনেকটাই সহজ হয়ে পড়বে। আমি বলছি না, একদম হার্ডকোর অংক অথবা পরিসংখ্যান শিখতে হবে - তবে আমাদের কাজে যতটুকু লাগে সেই ধারণাটা পাবার জন্য এই কাজটা জরুরি। পরবর্তীতে এই পরিসংখ্যান এবং অংকগুলো দিয়ে বিভিন্ন মডেল তৈরি অর্থাৎ মেশিন লার্নিং অংশে এই অংক এবং পরিসংখ্যান কিভাবে কাজ করে সেটা বোঝা সহজ হবে।
তত্ত্বকথার পাশাপাশি কিছু প্রোগ্রামিং এনভারমেন্ট জানা প্রয়োজন এই সেগমেন্টে। যাদের কোনো ধরনের প্রোগ্রামিং অভিজ্ঞতা নেই তাদের জন্য ‘আর’ প্রোগ্রামিং এনভায়রনমেন্ট অনেকটাই গডসেন্ড। যাদের প্রোগ্রামিং সম্বন্ধে ধারণা আছে তারা সরাসরি পাইথন দিয়ে শুরু করতে পারেন। তবে মেশিন লার্নিং অর্থাৎ ডাটা এনালাইসিস বুঝতে ‘আর’ প্রোগ্রামিং এনভায়রনমেন্ট এখনো উচ্চমানের ‘লার্নিং কার্ভ’ দিয়ে থাকে।
ডাটা থেকে প্রাপ্ত জ্ঞান থেকেই আমাদের সিদ্ধান্ত তৈরি করতে হয়। সেই পার্সপেক্টিভ থেকে ডাটা ‘ভিজুয়ালাইজেশন’ ব্যাপারটা বোঝার জরুরি। এই ডাটা ভিজুয়ালাইজেশন এর জন্য ‘আর’ এবং পাইথন প্রোগ্রামিং এনভায়রনমেন্টে অসাধারণ কিছু টুল তৈরি আছে অনেক আগে থেকে। ফাইনালি, এত জিনিস শেখার আমাদেরকে সরাসরি ‘টেস্ট’ করতে হবে রিয়েল লাইফ এনভায়রনমেন্টে। অর্থাৎ আমরা যা শিখলাম সেগুলো বাস্তব জীবনে ব্যবহার করতে পারছি কিনা, সেটাকে বোঝার জন্য করতে হবে বেশ কয়েকটা ক্যাপস্টোন অর্থাৎ ডাটা সায়েন্স প্রজেক্ট। সামারি শেষ, চলুন বিস্তারিত গাইড লাইনে।
বেসিক ‘এন্ড টু এন্ড’ পাইপলাইনের ধারণা (ঐচ্ছিক)
ডাটা সাইন্স এর বিগ পিকচার পাবার জন্য ‘মনিকা রোগাতি’র ডাটা সাইন্স এর ‘হায়ারার্কি অফ নিডস’ একটা আবশ্যিক জিনিস। এটা ঠিক মত বুঝতে পারলে পুরো রোডম্যাপটি মাথায় চলে আসবে। নিচের ছবিটা দেখুন। এর কয়েকটা ‘ভ্যারিয়েন্ট’ দেখা উচিত ইন্টারনেটে, অন্য লেভেলের পার্সপেক্টিভ বোঝার জন্য। ছবিগুলো ইংরেজিতেই রাখছি - ভালো বোঝার জন্য। তবে মাসলো’র তত্ব অর্থাৎ বেসিক ‘হায়ারার্কি অফ নিডস’ গুগল করে দেখা উচিত সবারই।
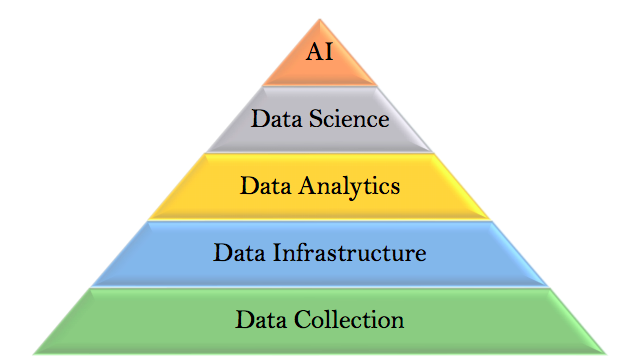
ডাটা সাইন্স এর ‘হায়ারার্কি অফ নিডস’ *
কয়েকটি ডায়াগ্রাম দেখুন। একটার সাথে আরেকটা কানেক্টেড। নিচের ছবিতে বিস্তারিত বলেছি।
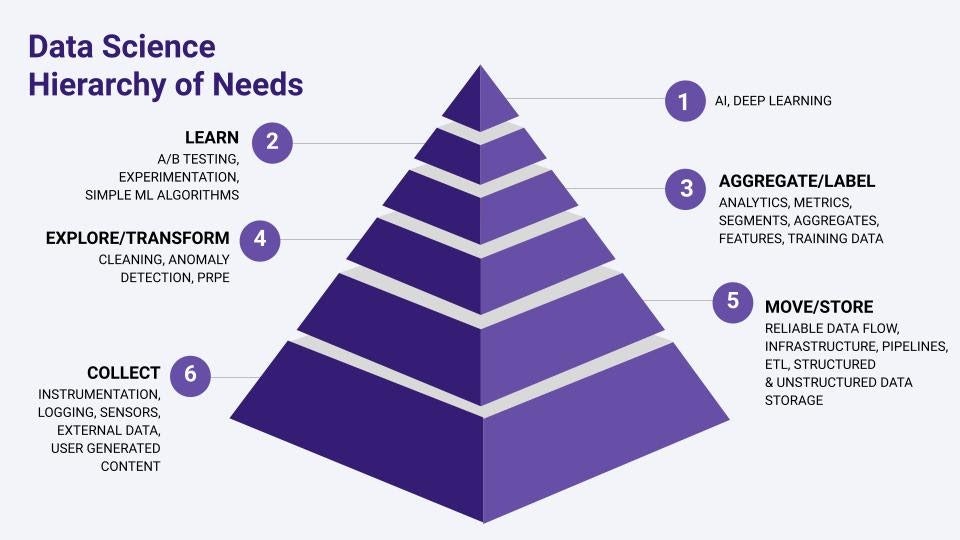
কাজের ধারনায়, উপরের ছবিটা অনেকটাই ইন্টারকানেক্টেড, তবে এটা বেসিক থেকে একটু বেশি ধারণা দেয়। কোথায় কাজ করতে চান আপনি, সেটার পার্সপেক্টিভ পাবেন এখানে। মাসলোর তত্ত্বের মধ্যে ডাটা সাইন্সের হায়ারার্কি অফ নিডস এর শুরুটা হচ্ছে ডাটা কালেকশন মেকানিজম দিয়ে। দিন শেষে ডাটা সাইন্সের কাঁচামাল হিসেবে ডাটাকে কালেক্ট করার জন্য এর প্রয়োজনীয় ইন্সট্রুমেন্টেশন, বিভিন্ন ডাটা লগ, বিভিন্ন ধরনের ডাটাসেট অর্থাৎ ডাটাবেজ, সেন্সর থেকে প্রাপ্ত ডাটা, ইত্যাদি ঠিকমতো কালেকশন করতে না পারলে এর পরবর্তী স্টেজে যাওয়া দুষ্কর। এই ছয় নম্বর সেগমেন্টে কি ধরনের টুল ব্যবহার প্রয়োজন - সেটার বিস্তারিত আলাপ থাকছে সামনে।
ডাটা কালেকশন হয়ে গেলে, এর জন্য স্টোরেজ এবং ইনফ্রাস্ট্রাকচার নিয়ে পঞ্চম ধাপ। এই ধাপে ডাটার রিলায়েবল ফ্লো, বিভিন্ন ধরনের পাইপলাইন, এর সাথে ‘ইটিএল’ অর্থাৎ ‘এক্সট্রাক্ট ট্রান্সফর্ম এবং লোড’ ভিত্তিক পাইপলাইনের ইনফ্রাস্ট্রাকচার তৈরি হয়ে গেলে চতুর্থ ধাপে যাওয়া সহজ হয়। চতুর্থ ধাপে ডাটার কিছু এক্সপ্লোরেশন, সঙ্গে ট্রানসফর্মেশন - যার মধ্যে ডাটা ক্লিনিং, অথবা ‘এনামলি ডিটেকশন’ ইত্যাদি ইত্যাদি করা সম্ভব। ডাটাকে ঠিকমত ক্লিন করা গেলে সেটাকে ট্রান্সফর্ম করে পাঠানো যেতে পারে তিন নাম্বার ধাপে।
এই তিন নম্বর ধাপটি খুবই গুরুত্বপূর্ণ - কারণ এখানে ডাটার এগ্রিগেশন, সম্ভাব্য লেবেলিং করা সম্ভব। ডাটার ভেতর থেকে জ্ঞান পাবার জন্য অ্যানালিটিকস (যেটা এই বইয়ের মূল লক্ষ্য), এর সঙ্গে বিভিন্ন ধরনের ‘ম্যাট্রিক্স’ এর ধারণা পাওয়া এবং তার সম্পর্কিত ‘ফিচার সেগমেন্টেশন’ এই ধাপে করা সম্ভব। এ কারণেই তৃতীয় ধাপ অনেকের কাছে খুবই আকর্ষণীয়। তবে, একদম শুরুর ষষ্ঠ ধাপ থেকে শুরু করলে ডাটা সাইন্স এর আসল কষ্টটা বোঝা যায়। বলতে গেলে, ডাটা কালেকশন এবং ডাটা ক্লিনিং সবচেয়ে কষ্টকর অংশ, যেখানে ডাটা সাইন্স এর প্রায় ৮০% সময় চলে যায়।
তৃতীয় ধাপে ডাটা অ্যানালিটিকস অর্থাৎ ডাটা থেকে ঠিকমতো জ্ঞান পাওয়া গেলে দ্বিতীয় ধাপ অর্থাৎ মেশিন লার্নিং (বেসিক লেভেলের) অ্যালগরিদম ব্যবহার থেকে শুরু করে বিভিন্ন ধরনের ‘এক্সপেরিমেন্টেশন’ যেমন এ/বি টেস্টিং, ( গুগল করে দেখুন) ধরনের বেসিক কাজগুলো এখানেই সম্ভব। সত্যি কথা বলতে, দ্বিতীয় ধাপের কাজ দিয়েই আমাদের অধিকাংশ প্রোডাক্ট ডেভলপমেন্ট করা যায়। তবে, আরো আধুনিক ডিপ লার্নিং মডেল এবং কৃত্রিম বুদ্ধিমত্তার কাজগুলো চলে যাবে শেষের প্রথম ধাপে যেখানে এই মুহূর্তে আমাদের মাথা না ঘামালেও চলবে। প্রতিটা ধাপের টুলগুলো ওপেনসোর্স ফ্রেমওয়ার্ক হিসেবে ব্যবহার হচ্ছে পৃথিবীজুড়ে। আমি যেটা বলতে চাইছি, ডাটা সাইন্স এর ‘হায়ারার্কি অফ নিডস’ এর সব টুল ওপেনসোর্স ফ্রেমওয়ার্কে পাওয়া যায়।
ডিপ ডাইভ: ‘হায়ারার্কি অফ ডাটা সাইন্স নিডস’ (সবার জন্য প্রযোজ্য নয়)
এই ব্যাপারটা গুরুত্বপূর্ণ বলেই নতুন করে লিখছি - যারা ডাটা সাইন্সে ক্যারিয়ার গড়তে চান। এখানে বেশকিছু জিনিস ‘রিপিট’ করছি যাতে একজন সাধারণ শিক্ষার্থী আরও ভেতরে ঢুকতে পারেন।
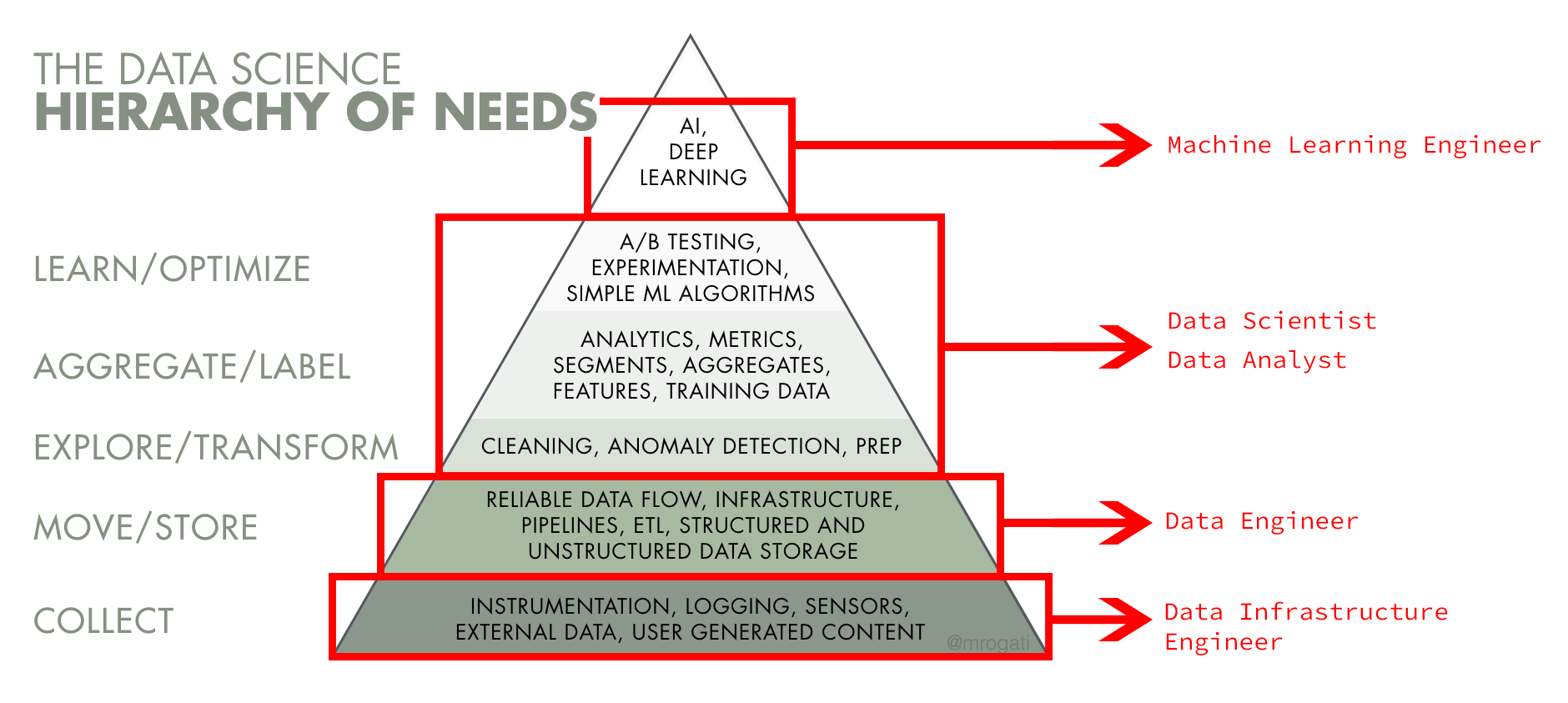
বড় বড় গল্প দেবার আগে ডাটা এনালিস্ট, ডাটা ইঞ্জিনিয়ার এবং ডাটা সাইন্টিস্ট এর মধ্যে পার্থক্য বুঝতে পারলে কাজগুলো খুব সহজ হয়ে যাবে। অনেকেই বুঝতে পারেন না তাদের জন্য কোন কাজটা নিজের স্কিলের সাথে যাবে অর্থাৎ তার কাজের প্রোফাইলের সাথে কোন স্কিলসেটটা যেতে পারে? এর পাশাপাশি আমাদের জীবনটাকে আরও কমপ্লেক্স(!) করার জন্য বিভিন্ন কোম্পানি তাদের জব পোস্টিং বিভিন্ন কথা বলে থাকেন - যা দেখে মনে হয় এই তিনটা ডেফিনেশনের মধ্যে নিজেরাই তালগোল পাকিয়ে ফেলছেন। এই ঝামেলা থেকে বের হওয়ার সবচেয়ে সহজ উপায় হচ্ছে জব পোস্টিংগুলোতে জব রেস্পন্সিবিলিটি (জব ডেস্ক্রিপশন) গুলোকে খুঁটিয়ে খুঁটিয়ে পড়া। এতে হেডিং এ কি বলা থাকছে অথবা থাকছে না - তার থেকে ভাল ধারণা দেবে ভেতরের ডেস্ক্রিপশন পড়লেই। সবচেয়ে মজার কথা হচ্ছে, এই ডেস্ক্রিপশন পড়লেই ওই কোম্পানিতে আমাদেরকে কি কাজ করতে হবে সেটা বোঝা যাবে সহজে। আর, এর ফলে ডাটা এনালিস্ট, ডাটা ইঞ্জিনিয়ার অথবা ডাটা সাইন্টিস্ট এর ‘ট্যাগলাইন’ অর্থাৎ ‘জব হেডিং’ বিবেচ্য নয়।
এই ঝামেলা থেকে বের হওয়ার জন্য আমরা আবারও আলাপ করছি ‘মনিকা রোগাতির’ “হায়ারার্কি অফ ডাটা সায়েন্স নিড” নিয়ে, তবে এবার আলোচনা করছি একদম ভেতরে গিয়ে। এই বিভিন্ন পজিশন নিয়ে আলাপ করার আগে আমাদের বোঝা উচিত - কিভাবে, কোথায় এবং কখন (অর্থাৎ কোন স্টেজে) এই ডাটাকে ব্যবহার করতে হয়। এই ছবিটা দেখে “ডাটা কালেকশন মেকানিজম” সম্বন্ধে আমরা যদি না জানি, তাহলে এর উপরের ডাটা সায়েন্স/মেশিন লার্নিং অথবা কৃত্রিম বুদ্ধিমত্তা নিয়ে কাজ করার কোন ফলাফল ঠিকমতো আসবে না। কৃত্রিম বুদ্ধিমত্তা পৃথিবীর সব সমস্যাগুলোর সমাধান অলৌকিকভাবে করে দেবে না এবং এর পাশাপাশি, আমাদের বর্তমান কাজে সব জায়গায় ‘কৃত্রিম বুদ্ধিমত্তা’ অথবা ‘মেশিন লার্নিং’ স্পেসিফিকভাবে লাগবেও না। ‘কৃত্রিম বুদ্ধিমত্তা’ অথবা ‘মেশিন লার্নিং’ নিয়ে কাজ করার আগে প্রচুর ছোট ছোট কাজ (লো হ্যাঙ্গিং ফ্রুট) আছে, যেগুলো করতে এত ঝামেলা পোহাতে হয়না। তবে, আমাদের বিজনেসে ডাটা ব্যবহার করতে হলে - সেই ডাটা কিভাবে স্টোর (সংগ্রহ, এবং সংরক্ষণ) করা আছে সেটা জানতে হবে আগে। বিভিন্ন জায়গা থেকে যখন ডাটা পাই, তখন সেই ডাটাকে ঠিকমতো স্টোর করার আগ পর্যন্ত সেটাকে কিভাবে ‘ম্যানুপুলেট’ করা হবে - সেটার ধারণা আসেনা।
আমাদের ডাটাকে ‘স্টোর’ করার জন্য কোন রিলেশনাল ডাটাবেজ অথবা সাধারণ “কমা সেপারেটেড ভ্যালু” অর্থাৎ “সিএসভি” অর্থাৎ খানিকটা এক্সেল ফরম্যাটে থাকুক না কেন, সেগুলোকে একটা জায়গা থেকে আরেকটা জায়গায় নেবার জন্য কিছু ডাটা পাইপলাইন তৈরি করতে হবে - যাতে একই ডাটা এক ফরম্যাট থেকে আরেক ফরম্যাটে ‘ট্রানসফর্ম’ করা যায়। শুরুতে এ ধরনের ডাটা পাইপলাইন ঠিকমত বোঝা না গেলেও বড় বড় কম্প্লেক্স সমস্যা সমাধানে এ ধরনের ডাটা পাইপলাইন যেকোন সমস্যাকে সহজ করে দেয়। এতে ডাটা এক জায়গা থেকে সরিয়ে আরেক জায়গায় তার দরকারি ফরমেটে স্টোর করা যায়। এধরনের কমপ্লেক্স তবে ডিস্ট্রিবিউটেড ডাটাবেজ সিস্টেমের জন্য - বিশেষ করে ডাটাকে এক জায়গা থেকে সরিয়ে আরেক জায়গায় নিজস্ব ফরমেটে রাখতে আমাদের প্রয়োজন হবে ডাটা ইঞ্জিনিয়ারদের।
এখানে এই পাইপলাইন লেখা মানে তৈরি করতে ডাটা ইঞ্জিনিয়ারদের ডাটা স্ট্রাকচার সম্বন্ধে ধারণা থাকা জরুরি। ডাটা ইঞ্জিনিয়ারদের একটা বড় কাজ হচ্ছে এই ডাটাগুলোকে ঠিকমতো ‘ক্লিন’ এবং ট্রানসফর্ম করা যাতে ডাটাগুলোকে ব্যবহার করা যায়। ডাটাকে ঠিক মত কোয়েরি করা না গেলে সেই ডাটার প্রয়োজন নেই। উদাহরণ হিসেবে, ডাটা প্রিপারেশন এর সময় যদি ডাটা ‘ডুপলিকেট’ হয়ে গেলে সেটাকে ‘ডি-ডুপ্লিকেট’ করার ধারণা থাকতে হবে আমাদের।এখানে “সিক্যুয়েল” (অথবা, অনেকের ভাষায় - এসকিউএল) দিয়ে ঠিকমতো ডাটাকে “কোয়েরি” করা গেলে আমাদের অনেক কাজই কমে আসবে। ডাটাকে ঠিকমত কোয়েরি করে সাধারণ কিছু “রেজুলেশন” ডাটার ভেতরের ধারণা সম্বন্ধে বেসিক ধারণা দিতে পারে এই পর্যায়ে।
এর পরে আসছে ডাটা এনালিস্ট, বিজনেস এনালিস্ট, প্রোডাক্ট ম্যানেজার, সফটওয়্যার ইঞ্জিনিয়ার - তারা সবাই ডাটাকে ‘কোয়েরি’ করে তাদের প্রশ্নের উত্তর বের করতে পারলে সমস্যা অনেকটাই সমাধানের পথে হাটতে পারি। এখানেই বিভিন্ন ধরনের ‘কোয়েরি’ চালিয়ে তাদের বিজনেস প্রবলেমগুলো সম্বন্ধে একটা ভালো ধারণা পাওয়া যায় - তার অ্যানালাইটিক্যাল অংশে। আমাদের প্রশ্নের অনেক উত্তর পাওয়া যায় - ঠিকমতো প্রশ্ন করতে পারলে এবং সেটা হবে এই স্টেজে। আমাদের অনেক প্রডাক্ট তৈরি এবং বিজনেস ডিসিশন আসবে এই অংশ থেকে। ‘ডাটা এনালিস্ট’ এর ডোমেইন এই অংশটুকু। যেহেতু আমরা এর মধ্যে দুটো বড় বড় স্টেজ পার হয়ে এসেছি - ফলে এই ‘ডাটা এনালাইসিস’ অংশে ডাটা ঠিকমত চলে এলে সঠিক কোয়েরি চালিয়ে বিভিন্ন প্রশ্নের উত্তর পাওয়া যাবে এই স্টেজে।
এর মধ্যে আমাদের চারটা স্টেজে ডাটাগুলোকে এমনভাবে ট্রানসফর্ম করা হয়েছে যাতে ডাটাগুলোকে দিয়ে আরো ‘গ্রানুলার’ কাজ করা যায়। এই স্টেজে দেখা যায় - বিভিন্ন ধরনের “এ/বি টেস্টিং ফ্রেমওয়ার্ক” যেখানে বিজনেস এর কোথায় কোথায় “ফাইন টিউনিং” করলে আলাদা আলাদা ধরনের প্রডাক্ট বিভিন্ন মানুষের কাছে পৌঁছানো সম্ভব। একটা প্রোডাক্টের “ইউ-এক্স” ডিজাইনের নীল নাকি লাল বাটনটা শেষমেশ কাজ করবে সেটা বোঝা যাবে এই ধারণা থেকে। এখানে বোঝা যাবে, কোন প্রোডাক্টের কোন কোন ফিচারগুলো আসলেই দরকারি এবং এর সাথে কোন ধরনের ‘ইনক্রিমেন্টাল চেঞ্জ’ প্রোডাক্টটাকে আরও আকর্ষণীয় করে তুলবে।
একই প্রডাক্টের ভিন্ন ভিন্ন ফিচার দিয়ে গ্রাহকের বিভিন্ন সেগমেন্টের এ ধরনের “এ/বি টেস্টিং” করতে পারলে সেটা একটা মজার জিনিস হবে। এখানে সাধারণ “লিনিয়ার রিগ্রেশন” অ্যালগরিদম চালিয়ে দেখতে পারি যাতে একজন ব্যবহারকারীর ভবিষ্যৎ বিহেভিয়ার ধরতে পারি - ভবিষ্যতে উনি কোন ফিচারগুলো আরো পছন্দ করবেন। এখানে আমাদের প্রয়োজন মত সাধারণ কিছু অ্যালগরিদম দিয়ে এ ধরনের টেস্ট প্রেডিক্ট করা যায় - যাতে ভবিষ্যৎ ব্যবহারকারীদের আচরণ আমরা আগে থেকেই ধরতে পারি।
সবচেয়ে উপরের স্টেজে কৃত্রিম বুদ্ধিমত্তা অথবা ডিপ লার্নিং নিয়ে কাজ করতে গেলে সবচেয়ে প্রথমেই প্রয়োজন ক্লিন ডাটা। আর, সে কারণেই আগের সবগুলো স্টেজে যেই পাইপ লাইনগুলো তৈরি করা হয়েছিল সেগুলোকে ঠিকভাবে কাজ করতে হবে। আমাদের ট্রেনিং ডাটাগুলোকে ঠিকমত ‘লেবেল’ করতে পারতে হবে - যাতে, আমাদের ভুলগুলো কমে আসে। এখানে আমাদের ‘প্রি-রিকুইজিট’গুলোকে ঠিকমত ‘আইডেন্টিফাই’ করতে পারলে উপরের স্টেজগুলোতে কাজ সহজ হয়ে যাবে। আমাদের আগের স্টেজে সাধারণ মেশিন লার্নিং অ্যালগরিদম যেমন, ‘লিনিয়ার ইকুয়েশন’ ইত্যাদি ইত্যাদি আশানুরূপ ফলাফল না দিলে এরপরের স্টেজে ‘ডিপ লার্নিং’ নিয়ে কাজ করা যেতে পারে।
জব ডেসক্রিপশন, কোথায় ডাটা এনালিস্ট, ডাটা ইঞ্জিনিয়ার এবং ডাটা সাইন্টিস্ট কাজ করবেন?
এখন আমাদের প্রশ্ন হতে পারে - এই পিরামিডের কোথায় কোথায় ডাটা এনালিস্ট, ডাটা ইঞ্জিনিয়ার এবং ডাটা সাইন্টিস্ট নিজেদেরকে ‘ফিট’ করাতে পারেন? আমাদের অভিজ্ঞতা বলে, ডাটা ইঞ্জিনিয়ার সাধারণত কালেকশন, এক্সপ্লোর এবং ট্রানসফর্মেশন ইত্যাদি নিয়ে কাজ করেন, সবচেয়ে নিচের দুটো ব্লকে। সফটওয়্যার ইঞ্জিনিয়ার সাধারণত কালেকশন পার্টটা নিয়ে কাজ করেন যাতে ‘ফ্রন্ট-এন্ড’ এবং ব্যাক-এন্ডে ঠিকমত যোগসুত্র করা যায়। কারণ, এখান থেকেই বিভিন্ন ধরনের ‘ইউজার ডাটা’ সংগ্রহ করা হয়। ডাটা এনালিস্ট সাধারণত কাজ করেন ‘এগ্রিগেট’ অথবা ‘লেবেলিং’ লেভেলে। এখানে ডাটাকে ‘এগ্রিগেট’ করে যাতে একটা ইনফর্মড ডিসিশন নেওয়া যায়, - এই স্টেজে আমাদের প্রশ্নের সচরাচর উত্তর আসে। আমরা সাধারণত: সিদ্ধান্ত নেই এই ডাটার উত্তর থেকে।
একজন ভাল এনালিস্ট এই ডাটা থেকে কোম্পানির ভবিষ্যৎ ‘ডাইরেকশন’ এবং কি কি জায়গায় কাজ (সেটা ফিচার অথবা প্রোডাক্ট হতে পারে) প্রয়োজন সেটা বের করতে পারেন। তারা টেকনিক্যাল এবং প্রোডাক্টের ‘ইনটুইশন’ নিয়ে বেশ ভাল ধারনা নিয়ে থাকেন, এর পাশাপাশি - তাদের ‘কমিউনিকেশন স্কিল’ অসাধারণ লেভেলের হতে হয়। এই কমিউনিকেশন স্কিল তাদেরকে কোম্পানির অন্যান্য সবাইকে এক ধারণায়/লেভেলে রাখতে সাহায্য করে। অনেক কোম্পানিতে, তাদের জব ডেস্ক্রিপশন অনুযায়ী ডাটা এনালিস্টকে ডাটা সাইন্টিস্ট হিসেবে দেখায়, যদিও ডাটা সাইন্টিস্টদের আরো বেশি টেকনিক্যাল স্কিলসেট থাকে। সে দিক থেকে একজন ডাটা সাইন্টিস্ট সাধারণ মেশিন লার্নিং মডেল থেকে শুরু করে কৃত্রিম বুদ্ধিমত্তার কিছু কিছু অংশ নিজে সলভ করে থাকেন।
এখানে অনেক সময় রিসার্চ সাইন্টিস্ট, এমএল ইঞ্জিনিয়ারের সহায়তায় কমপ্লেক্স উপরের সমস্যাগুলোকে সলভ করার চেষ্টা করেন। এই জব ডেসক্রিপশনে অনেকেই কাজ করেন - যারা ‘পিএইচডি ক্যান্ডিডেট’ হিসেবে থাকেন। তবে কোম্পানি ভেদে এই জিনিসগুলো বিভিন্নভাবে ডেলিভার হতে পারে। যেমন, এই অংশটুকু লেখার জন্য আমি সাহায্য নিয়েছি একজন “এক্স গুগলার” থেকে, তার নাম “জোমা”, যাকে গুগলে থাকার সময় সবকিছুই করতে হয়েছে। আবার, যারা ছোট স্টার্টআপ, তাদের একজন ডাটা সাইন্টিস্টকে সব কাজই করতে হয়। মোদ্দা কথা হচ্ছে, এখন থেকে যতো ডাটা সাইন্টিস্ট এবং ডাটা এনালিস্ট এর জব পোস্টিং দেখবেন, সব সময় জব ডেসক্রিপশন পড়ার চেষ্টা করবেন। এটাই আপনাকে সাহায্য করবে আসলেই সেই পজিশনটা আপনার জন্য ফিট করে কিনা।
এই পুরো জিনিসটি করতে আপনাকে সাহায্য করবে আমার প্রথম দুটো বই। ‘হাতে কলমে মেশিন লার্নিং’ বইয়ের অর্ধেক অংশ আলাপ করা হয়েছে আমার ব্যক্তিগত অভিজ্ঞতা এবং গল্প দিয়ে। দ্বিতীয় বই ‘শূন্য থেকে পাইথন মেশিন লার্নিং’ বইটা যেকোনো নন প্রোগ্রামিং ব্যাকগ্রাউন্ড এর ছাত্রছাত্রী শুরু করতে পারবেন কোন সমস্যা ছাড়াই। হাতে কলমে পাইথন এবং ‘আর’ প্রোগ্রামিং এনভায়রনমেন্ট (প্রোগ্রামিং এনভায়রনমেন্ট জানার দরকার নেই) দিয়ে হাটি হাটি পাপা করে পুরো জিনিসের পাইপলাইনগুলো বোঝানো হয়েছে খুব সহজ করে।
পাইপলাইন বুঝলে বেসিকভাবে একটা/দুটো ছোট (আসলেই ছোট) কয়েকলাইনের প্রজেক্ট করলেই একটা ধারণা চলে আসবে। বই কেনার দরকার নেই শুরুতে। প্রজেক্ট দুটো হচ্ছে,
| প্রজেক্ট | বইয়ের লিংক |
|---|---|
| আইরিস প্রজাতি প্রজেক্ট | শূন্য থেকে পাইথন মেশিন লার্নিং |
| টাইটানিক প্রজেক্ট | হাতেকলমে মেশিন লার্নিং |
এখন আমরা যেহেতু খুবই ভিজ্যুয়াল (ভিডিও দেখতে ভালোবাসি), সেকারণে এই ভিডিওটা একটা ভালো ধারণা দিতে পারে। এটা হাতেকলমে করলেই একটা বড় ধারণা চলে আসবে। শুরুতে না বুঝে করলেও আস্তে আস্তে বুঝে যাবেন করার সময়।
(পাইথন) ডাটা সাইন্স ওয়ার্কস্পেস, অ্যানাকন্ডা
কী নেই এখানে। মনে আছে, ডাটা সাইন্সের “হায়ারার্কি অফ নিডস” এর প্রতিটা ধাপের টুলগুলো ওপেনসোর্স ফ্রেমওয়ার্ক পাচ্ছেন এই অ্যানাকন্ডাতে। এতে আছে জুপিটারের নোটবুকসহ পুরো এনভায়রনমেন্ট। এর পাশাপাশি, কিছু না ইনস্টল করতে চাইলে আছে - গুগল কোলাবোরেটরি টুল।
বেসিক অংক, লিনিয়ার এলজেবরা, ক্যালকুলাস
ডাটা সায়েন্স এর ভেতরের খুঁটিনাটি জানতে শুরুতে লিনিয়ার এলজেবরা’’ একটা চমৎকার জিনিস। ডাটাকে প্রসেস করার আগে ওই ডাটাকে ঠিকমত কনটেইনারে রাখার জন্য স্কেলার, ভেক্টর এবং ম্যাট্রিক্স জানা জরুরী। বিশেষ করে লিনিয়ার এলজেবরা এর ভেতরে ভেক্টর এবং ম্যাট্রিক্স কিভাবে কাজ করে বিশেষ করে ট্রানসফর্মেশন, ইনভার্স, ট্রান্সপোজ এবং ম্যাট্রিক্স মাল্টিপ্লিকেশন, নিয়ে কিছু ধারনা নেয়া ভালো। ভেক্টরের মধ্যে ডট এবং ক্রস প্রডাক্ট কিভাবে করা যায়, সেটা খুব সহজেই শেখা যায় খান একাডেমি’’ থেকে। আমি নিজেও শিখেছি। এখানে লিনিয়ার ডিপেন্ডেন্সি, ইন্ডিপেন্ডেন্সি, এদের মধ্যে কম্বিনেশন, ইত্যাদি শেখা যায় ‘মিডিয়াম’ এর মত আরো অনেক সাইটে। তবে, সবকিছুর জন্য ভালো ‘খান অ্যাক্যাডেমি’। অথবা, বিভিন্ন ম্যাথ সাইট।
ক্যালকুলাসের জন্য কিভাবে ‘ডিরাইভেটিভ’ বের করতে হয়, ডিফারেন্সিয়াল ইকুয়েশন, - ‘ইন্টিগ্রালস’ এর সাথেই এমনি চলে আসে। সত্যি বলতে, এগুলো খুব সহজেই কয়েক লাইন দিয়ে তৈরি করা যায় পাইথন অথবা ‘আর’ প্রোগ্রামিং এনভায়রনমেন্ট দিয়ে। তবে, ভেতরের অংকটা জানা থাকলে কাজ করার সময় কিভাবে ভেতরে জিনিসগুলো শেষমেষ আউটকাম হিসেবে বের করেছে সেটা বোঝার সহজ হয়। অংক জানা ভালো, কারণ এতে ডাটা ইঞ্জিনিয়ারিং এর অংশ চমৎকার ভাবে বোঝা যায়।
পরিসংখ্যান, ডেস্ক্রিপটিভ, সঙ্গে ডিসট্রিবিউশন *
ডাটা সাইন্স এর পেছনে যে বিষয়টি সবচেয়ে বড় ভূমিকা রাখছে সেটা হচ্ছে পরিসংখ্যান। পরিসংখ্যানের সব ধারণাই মেশিন লার্নিং এ অর্থাৎ ডাটা সাইন্সে ঢুকে গেছে যখন ডাটা প্রসেসিং চলে এসেছে কম্পিউটারের ভেতরে। ডেস্ক্রিপটিভ স্ট্যাটিসটিকস এবং ডাটার ডিসট্রিবিউশন ঠিকমত বোঝা গেলে ডাটা সায়েন্স বোঝা অনেকটাই সহজ হয়ে যায়। ডাটার মধ্যে সর্বোচ্চ, সর্বনিম্ন, মিডিয়ান, মোড, গড়, সেন্ট্রাল টেন্ডেন্সি ইত্যাদি ডাটার ভেতরের ইতিহাস বের করে দেয়। ডাটার ‘নর্মাল ডিস্ট্রিবিউশন’ বোঝার জন্য খুব সাধারণ কয়েকটা লেসন ইন্টারনেটে পাওয়া যায় খুব সহজে।
এর পাশাপাশি হিস্টোগ্রাম, স্ক্যাটার প্লট এবং বক্স প্লট করার ধারণা চলে এসেছে সবার ঘরে ঘরে। ডাটার ভ্যারিয়েন্স এবং স্ট্যান্ডার্ড ডেভিয়েশন জিনিসগুলো সহজেই বোঝা যাচ্ছে খান একাডেমির কল্যাণে। এগুলো এখন সাধারণ অংকের মধ্যেই পড়ে। যে কোন জিনিসের ‘কনফিডেন্স ইন্টারভ্যাল’ এবং ‘হাইপোথিসিস টেস্টিং’ চলে এসেছে রিসার্চের সাথে সাথে। এগুলো সব চলে আসছে পপুলেশন প্রপোরশন, ‘পি ভ্যালু’ এবং ‘সিগনিফিকেন্স টেস্ট’ করতে গিয়ে। দুষ্ট লোকেরা এটার সাথে ‘এসপিএসএস’ প্যাকেজ মেলাবেন। প্রথম প্রথম এগুলো কঠিন মনে হলেও আসলে ব্যাপারগুলো অনেক সোজা। একটু গুগল করেই দেখুন না!
প্রোবাবিলিটির কোর কনসেপ্টগুলো খুব একটা সমস্যা না করলেও এর ভেতরের এক্সপেরিমেন্টাল প্রোবাবিলিটি, ইন্ডিপেন্ডেন্ট এবং ডিপেন্ডেন্ট ইভেন্ট, কন্ডিশনাল প্রোবাবিলিটি জানা ভালো। এ ব্যাপারে, গুগল ‘কিওয়ার্ড’ এবং খান অ্যাক্যাডেমি আমাদের হাতের পাঁচ।
প্রোগ্রামিং স্কিল, পাইথন/‘আর’ এনভায়রনমেন্ট *
আগেই বলেছি - ডাটা সায়েন্স অথবা ডাটা অ্যানালাইটিক্স ঠিকমতো কাজে লাগাতে গেলে একটা প্রোগ্রামিং এনভায়রনমেন্ট জানা প্রয়োজন। এখানে বিশ্বখ্যাত দুটো প্রোগ্রামিং এনভায়রনমেন্ট নিয়ে কথা বলছি - ডাটা সায়েন্স এবং ডাটা এনালাইটিক্স ঠিকমতো শুরু করার জন্য। প্রোগ্রামিং (“আর” অথবা পাইথন প্রোগ্রামিং এনভায়রনমেন্ট) নিয়ে আমাদের অনেকের মধ্যে কনফিউশন তৈরি হয়েছে, বিশেষ করে এর ডাটা সাইন্সের ব্যবহার নিয়ে। শুরুতে বুঝতে হবে, আমরা কেন প্রোগ্রামিং এনভায়রনমেন্ট ব্যবহার করি ডাটা সাইন্সে? যেকোন সমস্যার শুরুতে ধারণা পেতে আমাদের ডাটা “পুল” করতে হয় বিভিন্ন ডাটাসেট থেকে। ডাটা সাইন্সে, সেই ডাটা টেনে আনার জন্য আমরা ব্যবহার করি ‘এপিআই’ (অ্যাপ্লিকেশন প্রোগ্রামিং ইন্টারফেস), (ডাটাসেট থেকে আনা), অথবা ‘স্ক্র্যাপিং’’ (ওয়েবসাইটগুলো থেকে বিভিন্ন ডাটা টেনে আনা) এর মাধ্যমে। এর পাশাপাশি, ডাটা ম্যানুপুলেশন এবং ট্রান্সফর্মেশনে (ইটিএল) ব্যবহার করি প্রোগ্রামিং। এই জায়গাগুলোতেই প্রোগ্রামিং এনভায়রনমেন্ট ব্যবহার হয়, তার আগে নয়।
‘আর’ প্রোগ্রামিং এনভায়রনমেন্ট
যারা নন-প্রোগ্রামিং ব্যাকগ্রাউন্ড থেকে আসেন, তাদের জন্য ‘আর’ প্রোগ্রামিং এনভায়রনমেন্ট অনেকটাই ‘গডসেন্ড’। কারণ, পরিসংখ্যানের জন্য স্পেসিফিক্যালি তৈরি করা হয়েছিল এই ‘আর’ প্রোগ্রামিং টুল, যা ডাটা সাইন্স/ডাটা অ্যানালিটিক্স এর শুরুটা ধরতে অসাধারণভাবে সাহায্য করে। যে কাজটা হয়তোবা পাইথনের করতে পাঁচ লাইনের কোড প্রয়োজন পড়তো, সেটা হয়তোবা একলাইনেই করে ফেলতে পারে ‘আর’ এর হাজারো লাইব্রেরি। এর পাশাপাশি, ডাটা ভিজুয়ালাইজেশন এর জন্য ‘আর’ এর অসাধারণ কিছু টুল এখনো বিশ্বসেরা। এর ভাল ধারণা পাওয়ার জন্য আমার প্রথম বই ‘হাতে কলমে মেশিন লার্নিং’ দিয়ে শুরু করা যায়। ক্লাস টেনের শিক্ষার্থীও বুঝবেন ব্যাপারগুলো।
পাইথন প্রোগ্রামিং এনভায়রনমেন্ট
যাদের আগে থেকে প্রোগ্রামিং এর ধারণা আছে, তারা সাধারণত পাইথন দিয়ে ডাটা সাইন্স এবং ডাটা এনালাইটিক্স শুরু করেন। ‘আর’ এর মত পাইথন এর বহু ডাটা সায়েন্স লাইব্রেরী সহজ করে দিচ্ছে এই ডাটা সাইন্স জার্নিকে। পাইথন দিয়ে ডাটা সায়েন্স শেখার জন্য আমার ‘শূন্য থেকে পাইথন মেশিন লার্নিং’ বইটা দেখা যেতে পারে। এর পরের বইটা “হাতেকলমে পাইথন ডিপ লার্নিং” অ্যাডভান্সড লেভেলকে নিয়ে এসেছে সহজ করে।
(পাইথন) দিয়ে ডাটার চারটি কাজ
পাইথন দিয়ে ডাটা সায়েন্স অথবা ডাটা অ্যানালিটিক্স বোঝার জন্য পুরো ব্যাপারটাকে চার ভাগে আলাদা করে ফেলি। ডাটা নিয়ে কাজ করতে গেলে প্রথমে আমাদের হাত দিতে হবে ‘ডাটা কালেকশন’ এ। এর মানে, ডাটাকে যদি ঠিকমতো আমাদের সিস্টেমে লোড না পারলে - কোন কাজই ঠিকমতো শুরু করা যাবে না।
(পাইথন) ডাটা কালেকশন
ডাটা কালেকশন করতে গেলে বেসিক লেভেল এ পাইথনের বেশকিছু লাইব্রেরী ব্যবহার করব যার মধ্যে পান্ডা খুব নামকরা। সত্যি কথা বলতে, এই ‘পান্ডাজ’ দিয়ে হেন কাজ নেই যা করা যায় না। এর একটু এডভান্স লেভেলে গেলে ‘সেলেনিয়াম’ এবং ‘স্ক্রাপি’ ব্যবহার করা যায়। গুগল করুন এই দুটো কীওয়ার্ড।
এক্সপ্লোরাটরি ডাটা এনালাইসিস, ইডিএ *
এর পরের ধাপ হচ্ছে ডাটা এনালাইসিস। যেকোনো ডাটা কালেকশন করার পর সেটাকে ঠিকমত ক্লিন এবং ট্রানসফর্মেশন করতে আমাদের প্রয়োজন বেশকিছু পাইথন লাইব্রেরী। ডাটা থেকে ঠিকমতো ইনসাইট পেতে ডাটা কালেকশন এর মতো একই ধরনের লাইব্রেরী ব্যবহার করলেও এখানে বেশ কিছু নতুন ধারণা চলে আসছে। এক্ষেত্রে ডাটা কিভাবে স্টোর হয় এবং সেই ডাটাকে কিভাবে ম্যানিপুলেশন করা যায় সেটার জন্য আমরা ব্যবহার করব (numpy) নামপাই এবং পান্ডাজ লাইব্রেরী। এটাকে আমরা ‘এক্সপ্লোরাটরি ডাটা এনালাইসিস’ বলি যা আমাদেরকে ডাটাকে ঠিকমতো এক্সপ্লোর করতে দেয়, এর ভেতরের প্যাটার্ন বোঝার জন্য।
ডাটা ভিজুয়ালাইজেশন (ইডিএ, এক্সপ্লোর) *
ডাটার ভেতরে ঠিক প্যাটার্নটা বুঝতে আমাদের প্রয়োজন ডাটা ভিজুয়ালাইজেশন। মানুষের মাথা অসাধারণভাবে প্যাটার্ন বুঝতে পারে বলে - সেই ডাটাকে যখন বিভিন্ন অ্যাক্সিস এ প্লট করা হয়, তখন সেগুলোর মধ্যে প্যাটার্ন বা সম্পর্কগুলো উঠে আসে। শুরুতে বার, বক্স প্লট এবং পাই চার্ট একটা ভাল ধারণা দেয় - কিভাবে ডাটাগুলো নিজেদের বিভিন্ন ফিচারের মধ্যে ‘ইন্টার কানেক্টেড’। এটা বুঝতে শেখায় পৃথিবীতে সবকিছুই একটা প্যাটার্নে চলে - যার অনেকটাই আমাদের অজানা। এই কাজটি করতে পাইথনের ‘ম্যাট-প্লট-লিব’ এবং ‘সিবর্ন’ লাইব্রেরিগুলো চমৎকার কাজ করে।
বিজনেস অ্যানালিটিকস এবং ইন্টেলিজেন্স টুল *
94% of people using data in their current job role agree that data helps them do their job better.
ডাটা থেকে ঠিকমত ধারণা নিয়ে সেটাকে স্টেকহোল্ডার (যারা আমাদের সিনিয়র ম্যানেজমেন্ট অথবা কাস্টমার)কে ঠিক মত কমিউনিকেট করতে হলে ডাটার ভেতরে কি ধরনের অ্যানামোলি/সম্পর্ক আছে সেটার জন্য স্ক্যাটার প্লট, বক্স প্লট ইত্যাদি ইত্যাদি তৈরি করতে কিছু প্রফেশনাল বিজনেস অ্যানালিটিকস এবং ইন্টেলিজেন্স টুল ব্যবহার করতে হয়। ওপেনসোর্স টুল হিসেবে সিবর্ন ভালো, তবে অল্প সময়ের মধ্যে ভালো এনালাইটিক্স এবং বিজনেস ইন্টেলিজেন্স টুল হিসেবে মাইক্রোসফট এক্সেল, গুগলশিট, ট্যাবলিউ এবং মাইক্রোসফট পাওয়ার বিআই অন্য লেভেলের জিনিস। ডাটা থেকে অ্যাডভান্সড এনালাইটিক্স বোঝার জন্য এই কয়েকটা টুল অসাধারণ কাজ করে। মাইক্রোসফট এক্সেল, ট্যাবলিউ এবং মাইক্রোসফট পাওয়ার বিআই নিয়ে আমার অনেকগুলো ভিডিও আছে।
এক্সেল, গুগলশিট, ট্যাবলিউ, পাওয়ার বিআই *
আগেই বলেছি, ওপেনসোর্স টুল হিসেবে পাইথন চমৎকারভাবে কাজ করলেও বড় বড় ব্যবসায়িক প্রতিষ্ঠান ডাটা নিয়ে কাজ করার জন্য অনেক ধরনের ‘প্রোপাইটোরি’ টুল ব্যবহার করে থাকেন। এধরনের ‘প্রোপাইটোরি’ টুলগুলো শুধুমাত্র স্মার্ট নয়, একজন ব্যবহারকারীকে কত সহজে নানা ধরনের রিপোর্ট অল্প সময়ের মধ্যে বের করে দিতে পারে সেটা নিয়েই চলছে হাজারো গবেষণা। যেহেতু সবকিছুকে তৈরি করা হচ্ছে ব্যবহারকারীর চাহিদাকে মাথায় রেখে, সে কারণে এ ধরনের টুলগুলোর দাম নির্ধারণ হয় তাদের কাজের কম্প্লেক্সিটির ওপর। সবার কম্পিউটারে মাইক্রোসফট এক্সেল সেটারই প্রমাণ। এর পাশাপাশি গুগলশিট, বিনামূল্যে সার্ভিস দিলেও কর্পোরেট ডাটার ব্যাপারে কিছু সীমাবদ্ধতা রয়েছে। বিজনেস অ্যানালিটিক্স নিয়ে ট্যাবলিউ, পাওয়ার বিআই অন্য লেভেলের জিনিস। তবে এর খরচ কম নয়।
(পাইথন) মডেল তৈরি, মেশিন লার্নিং
ডাটা সায়েন্স এর শেষ পর্যায়ে থাকছে কিভাবে ডাটা থেকে ধারণা নিয়ে মডেল তৈরি করতে হয়। ডাটা এনালাইটিক্স এবং এক্সপ্লোরাটরি ডাটা এনালাইসিস থেকে যেই জ্ঞানটা পাচ্ছি সেটাকে মডেলে নিয়ে আসতে আমাদের প্রয়োজন মেশিন লার্নিং। এই অংশটুকু ডাটা এনালাইটিক্স এ থাকছে না। এই মডেল তৈরি এবং মডেল থেকে প্রাপ্ত জ্ঞানগুলোকে কিভাবে ব্যবহার করতে হয় সেটার পেছনে স্ট্যাটিসটিকস অর্থাৎ পরিসংখ্যান এবং অংকের সাহায্য লাগবে। আমি আবারো বলছি, অংক এবং পরিসংখ্যান এর সব কাজে বিভিন্ন টুল ব্যবহার করে করলেও এর পেছনের ‘আন্ডারলায়িং’ আন্ডারস্ট্যান্ডিং আসবে অংক এবং পরিসংখ্যান থেকে। বিশেষ করে, মডেলগুলো কিভাবে কাজ করছে সেটা বুঝতে।
এই জায়গায় বেসিক লেভেল এ আমরা ব্যবহার করব পাইথনের scikit-learn এবং ডিপ লার্নিং এর জন্য ‘টেনসরফ্লো’ ফ্রেমওয়ার্ক। যারা রিসার্চে কাজ করতে চান তাদের জন্য পাইটর্চ লাইব্রেরিটা খারাপ নয়। পাইথনের scikit-learn লাইব্রেরি বিশ্বের অন্যতম ভালো ডকুমেন্টেড লাইব্রেরী যা শেখা খুবই সহজ। আমার দ্বিতীয় বই ‘শূন্য থেকে পাইথন মেশিন লার্নিং’ এ ব্যাপারে চমৎকার ধারণা দিয়েছে। ‘টেনসরফ্লো’ ফ্রেমওয়ার্ক অর্থাৎ ‘ডিপ লার্নিং’ নিয়ে কাজ করতে চাইলে আমার কিছুটা অ্যাডভান্সড বই ‘হাতেকলমে পাইথন ডিপ লার্নিং’ ব্যবহার করতে পারেন।
সিক্যুয়েল স্কিল, SQL *
ডাটা কালেকশন করার জন্যে বিভিন্ন টুল ব্যবহার করলেও সেই ডাটা কোথায় আছে সেটা নিয়েও অনেক কাজ করার স্কোপ রয়েছে। সে কারণে রিলেশনাল ডাটাবেজ কিভাবে কাজ করে তার কনসেপ্ট কি, কিভাবে সিক্যুয়েল কুয়েরি দিয়ে একটা ডাটাবেজ থেকে তার আউটকামস বের করে আনা যায় সেটা জানা জরুরি। ডাটা সায়েন্স এবং ডাটা অ্যানালাইটিকসের জন্য সিক্যুয়েল একটা কার্যকরী মেকানিজম।
ডাটাবেজে কোয়েরি করার জন্য সিক্যুয়েলের বিভিন্ন স্টেটমেন্ট, যেমন ‘ডিডিএল’ হিসেবে create, alter, drop, truncate, rename, ডিএমএল স্টেটমেন্ট হিসেবে, select, insert, update, delete, এবং শেষে বিসিএল স্টেটমেন্ট হিসেবে grant, revoke, টিসিএল স্টেটমেন্ট হিসেবে commit, rollback ইত্যাদি জানা প্রয়োজন। এর পাশাপাশি বিভিন্ন টেবিলকে কিভাবে জয়েন, ইউনিয়ন করতে হয় তা জানা জরুরী। এখানে শুরুতে ওপেনসোর্স ডাটাবেজ ফ্রেমওয়ার্ক ‘মাইএসকিউএল’ নিয়ে কাজ করা যায়।
নো সিক্যুয়েল (ঐচ্ছিক)
সিক্যুয়েল এর পাশাপাশি আন-স্ট্রাকচার্ড ডাটার জন্য নো সিক্যুয়েলের জনপ্রিয়তা বাড়ছে দিনে দিনে। নন-টেবুলার এবং রিলেশনাল ডাটাবেজ নয় - এধরনের ক্ষেত্রে এর কাজ অসাধারণ। এই পার্সপেক্টিভ থেকে ‘মঙ্গোডিবি’ নিয়ে কাজ করা যেতে পারে। এই ধারণাগুলো ভবিষ্যতে কাজে লাগবে।
ডাটা সাইন্স/অ্যানালিটিক্স ক্যাপস্টোন প্রজেক্ট
একটা জিনিস পুরোপুরি বুঝতে গেলে কাজের পাইপ লাইন ধরে শুরু থেকে শেষ পর্যন্ত একটা সত্যিকারের প্রজেক্ট না করলে পুরো শেখাটাই বিফলে যেতে পারে। সে কারণে ডাটা সায়েন্স এবং ডাটা অ্যানালাইটিকসের জন্য কিছু ইন্ডাস্ট্রি সম্পর্কিত ক্যাপস্টোন প্রজেক্ট করতে হবে। এতে সবগুলো বিষয় যা বলেছি, সেগুলোর ফাউন্ডেশন ধারনাগুলোকে রিয়েল ওয়ার্ল্ড সিনারিওর সাথে যুক্ত করা যাবে।
গ্লোবাল সুপারস্টোর প্রজেক্ট (অ্যানালিটিক্স) *
এখানে আমরা কিছু কাজ দেখাবো, সুপারস্টোর ম্যানেজমেন্ট নিয়ে। মাথা খারাপ করা একটা রিয়ালিস্টিক প্রজেক্ট।
মুভি রিকমেন্ডেশন প্রজেক্ট
নেটফ্লিক্স এবং ইউটিউব যেভাবে আমাদেরকে রিকমেন্ড করে সেই একই পদ্ধতি ব্যবহার করে আজকে দারাজ, আলীএক্সপ্রেস, আমাজন তাদের প্রোডাক্ট রিকমেন্ড করে -যেটা ব্যবহারকারী হিসেবে আমরা দেখে অথবা কিনে থাকি। এধরনের মুভি এবং প্রোডাক্ট রিকমেন্ডেশন প্রজেক্ট নিয়ে কাজ করলে রিয়েল ওয়ার্ল্ড সিনারিওর সাথে আমাদের শেখাকে সংযুক্ত করা যায়। এখানে একটা সিম্প্লিফাইড মুভি রিকমেন্ডেশন সিস্টেম বানাতে পারলে পৃথিবীর ই-কমার্সের বিশাল একটা অংশ মাথায় নিয়ে আসা সম্ভব।
কাস্টমার চার্ণ ম্যানেজমেন্ট প্রজেক্ট
যে কোন কোম্পানির জন্য তার কাস্টমার বড় সম্পদ। কোন কাস্টমার তার সাথে থাকবেন অথবা তার প্রোডাক্ট ব্যবহার না করে অন্য প্রোডাক্টে সুইচ করবেন, সেটা আগে থেকে বুঝতে পারলে ব্যবসা সহজ হয়ে যায় অনেক জায়গায়। একটা মোবাইল ফোন কোম্পানি তাদের পুরনো ব্যবহারকারীকে কিভাবে ফিরিয়ে আনবেন অথবা কোন কোন কাস্টমার কেন এবং কখন সুইচ করে অন্য কোম্পানিতে চলে যাচ্ছেন, অথবা একটা কোম্পানি থেকে একজন এমপ্লয়ি কবে অন্য কোম্পানিতে সুইচ করবেন - সেটা আগে থেকে জানা গেলে মানবসম্পদ অর্থাৎ এইচআর ডিপার্টমেন্ট অনেক অপ্রীতিকর ঘটনা কমিয়ে আনতে পারেন।
কাজের পোর্টফোলিও ‘শো-কেসিং’ *
প্রজেক্টে কাজ করার পাশাপাশি সেই কাজগুলো অন্যদেরকে দেখানো ( ‘শো-কেসিং’) জরুরী। এতে ভালো ফিডব্যাক পাওয়া যায়। নিজের আত্ববিশ্বাস বাড়ে। একটা জিনিস কিভাবে শিখলাম এবং সেটাকে কিভাবে ডেলিভারি দিতে পারছি - সেটার একটা ভালো যোগসূত্র হচ্ছে - আমাদের সবগুলো কাজের ‘পোর্টফোলিও’ সাইট তৈরি করা। যেকোনো ডাটা সাইন্স এবং ডাটা এনালিস্ট কাজ পেতে এ ধরনের ‘শো-কেসিং’ জরুরি। শুরুর দিকে ‘শো-কেসিং এর জন্য - বিশেষ করে এ ধরনের সাইট তৈরিতে গিটহাব পেইজ অসাধারণ কার্যকারিতা দেয়। এই সাইটটাও সেই গিটহাব পেইজ দিয়ে তৈরি করা। এর পাশাপাশি, নেটওয়ার্কিং ইভেন্টগুলোকে কানেক্ট করতে হবে সেখানে।
ঐচ্ছিক: ডাটা ইঞ্জিনিয়ারিং, এপিআই
ঐচ্ছিক বিষয় হিসেবে ডাটা ইঞ্জিনিয়ারিং এবং তার ডেপ্লয়মেন্ট, এর পাশাপাশি এদের মধ্যে এপিআই ভিত্তিক যোগাযোগ, বিশেষ করে জেসন ফাইল, রেস্ট, ওপেন এপিআই ইত্যাদি নিয়ে ধারণা থাকলে যেকোন ইকোসিস্টেমে এই কাজ সহজে ফিট করতে পারবে। এর সাথে, গ্রাফ থিওরি, নেটওয়ার্ক এনালাইসিস, টাইম সিরিজ এনালাইসিস, অপটিমাইজেশন, কম্বিনেটরিক্স মাঝে মধ্যে ভালো কাজে লাগে।
ডাটা সাইন্স কমিউনিটি তৈরি
আমদেরকে তৈরি করতে হবে।
ডাটা সাইন্স/অ্যানালিটিক্স শুরুতে প্রথম ৪টা বাংলা বই
